ယူနီကုဒ် ရှင်းတမ်း
ဒီရက်ပိုင်း ယူနီကုဒ်ကို လူတော်တော်များများ စိတ်ဝင်စားလာကြပြီး ထောက်ပြဝေဖန်မေးမြန်းတာတွေ ရှိတဲ့အထဲမှာ ညီလင်းဆက်ရေးခဲ့တဲ့ Review on Myanmar Unicode 5.1 & Suggestion ကို ပြတဲ့ပြီး ဒါတွေရှင်းပြီးပြီလားလို့ မေးတဲ့လူတွေ ရှိလာလို့ ဒီစာကို ရေးဖြစ်ပါတယ်။ ယူနီကုဒ်လုပ်ခဲ့တဲ့ ပညာရှင်တွေ၊ Developer တွေက ကိုယ်စီ ရှင်းထားကြပေမဲ့ အင်္ဂလိပ်လိုဖြစ်တာရယ်၊ မြန်မာလိုရေးထားတာဆိုရင်လည်း တစ်စုတစ်စည်းတည်း မရှိတာကြောင့် တစ်နေရာတည်းမှာ စုစည်းပြီး ဖြေပေးလိုက်ပါတယ်။
၁။ 
ယူနီကုဒ်မှာ ပုံသဏ္ဌာန် ထပ်တူထပ်မျှတူရင် သုံးတဲ့နေရာ မတူပေမဲ့ ကုဒ်ပွိုင့်တစ်ခုတည်း ယူပါတယ်။
ဥပမာ –
玍 – (738D)
To be born
Birth, origin
To live, to exist, to survive
To revive, to bring to life
Raw, uncooked, crude
Pure, neat, genuine
unfamiliar, strange
untamed, barbarian
a student
ះ – (17C7)
KHMER SIGN REAHMUK
srak ah
visarga
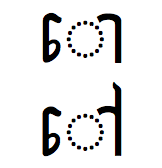
Khmer O, AU
ရှေ့ထိုး (ေ-ာ်)ကိုသီးခြားခွဲထုတ်မရပါ။ ဒါ့အပြင် Split Vowel (ခမာတွင်သုံးသည်, 17C4, 17C5) ဟုသတ်မှတ်၍ ေ-ာ်အတွက် တစ်ကွက်ထည့်ပါက ေ-ာ၊ -ံ့ ၊ -ို အတွက်ပါ ထည့်ရပါမယ်။ အဲဒီအတွက် Split Vowel ကိုမသုံးပဲ အသတ်ကိုသာ ရှေ့ထိုးအတွက် ပုံဖော်ခြင်းမှာ သုံးပါတယ်။ အဲလိုမျှဝေသုံးစွဲခြင်းအတွက် အက္ခရာစဉ်ခြင်းနှင့် ရှာဖွေခြင်းတွင် မည်သို့မျှပြောင်းလဲခြင်းမရှိပါ။ Split Vowel လို့ထည့်ရင် ပြင်မယ်ဆိုရင် အသတ်ကိုဖျက်တာ၊ ရေးချကို ဖျက်တာခက်သွားမယ်။ ကော် ကနေ ကော၊ ကေ ကိုပြင်မယ်ဆိုရင် ရေးချ၊ ရှေ့ထိုးဖျက်ရုံနဲ့မရဘဲ တစ်ခုလုံးဖျက်ရပါမယ်။
၂။ 
မွန်ဘာသာ ရှေးစာတွေမှာ “ပဿ” အသုံးရှိသလို “လသ္သ” အသုံးလည်း ရှိပါတယ်။ ယူနီကုဒ် အရှေ့ပိုင်းဗားရှင်းတွေမှာ ဿကြီး မပါပါဘူး။ နောက်မှ လိုလို့ အကြောင်းအကျိုး သက်သေသာဓကတွေ ပြပြီး တောင်းထားတာ ဖြစ်ပါတယ်။ နောက်ထပ် code point မပေးရင် အဲဒီ ၂ခုလုံးကို ဖော်ပြဖို့ မဖြစ်နိုင်ပါ။ disunification လုပ်ရပါတယ်။ Database မှာ De-normalization ကို မြန်ဖို့ အဆင်ပြေဖို့ သုံးရသလိုပါပဲ။
၃။ 
ခုခေတ်မှာ ဗမာစာတစ်ခုတည်း ရုံးသုံးဖြစ်နေပေမဲ့ တူညီတဲ့ အက္ခရာတွေ ယူသုံးတဲ့ တခြားသာသာစကား အများအပြားလည်း ရှိပါတယ်။ ယူနီကုဒ်မှာ ဗမာ၊ မွန်၊ ရခိုင်၊ ရှမ်း၊ ပိုးကရင်၊ စကောကရင်၊ ပလောင်၊ ပအို့ဝ် စတဲ့ တိုင်းရင်းသားစာ အများအပြားအတွက်ပါ ထည့်ပေးထားတဲ့အတွက် ဗမာစာတစ်ခုတည်း ကွက်ကြည့်လို့ မဖြစ်တော့ပါဘူး။ ဗမာစာကိုယ်တိုင်ကိုက မွန်အက္ခရာတွေမှာ အခြေခံထားတဲ့အတွက် မွန်ဘာသာရယ်၊ သူနဲ့ယှဉ်ပြီးသုံးတဲ့ ရှေးထုံးဗမာစာရယ်ကိုပါ ထည့်စဉ်းစားရပါတယ်။ မွန်စာရေးထုံးအရ မသတ် (မ်) ကို အတိုရေးချင်တဲ့အခါ ဗျည်းပေါ် အစက်တင် (Superscripted) ရေးပါတယ်။ (အခုထိ ခမာမှာ အဲဒီအတိုင်းသုံးပါတယ်)။ အမှန်တော့ ဗျည်းပေါ်တင်ရေးတဲ့ အဲဒီအစက် ကိုယ်တိုင်ကိုက ဗျည်း(အံ) ဖြစ်ပါတယ်။ အဲဒါကြောင့် အ နဲ့ပေါင်းပြီး အ သေးသေးတင် ဖြစ်တဲ့အခါ သရလို့ မယူဆပါဘူး။ နောက်ပိုင်း မြန်မာသင်ပုန်းကြီးက ဗျည်းမှာ အံ မထည့်တော့ဘဲ ဗျည်းလွတ်နေတဲ့ သရတွေကို စီတဲ့အထဲ သွားထည့်လိုက်တဲ့အခါ သရအဖြစ် သတ်မှတ်လိုက်ပါတော့တယ်။ အဲဒါကြောင့် သေးသေးတင်ကို သရအဖြစ်ရော ဗျည်းအဖြစ်ပါ သတ်မှတ်တဲ့အတွက် Various Sign ထဲထည့်ပါတယ်။ ခမာနဲ့ ထိုင်းဘာသာတွေမှာပါ Various Sign ထဲ ဝင်ပါတယ်။
၄။ 
ရှေးက မြန်မာစာရေးတဲ့အခါမှာ ကျောက်စာပေစာတွေမှာ ရေးရတဲ့အတွက်တွက် နေရာဆံ့အောင်င် အတိုရေးရတဲ့ နည်းတွေ ရှိပါတယ်။ အု က ဥ ဖြစ်တာတွေကတွေက အဲဒီထုံးပါပဲ။ ၎င်း ကိုယ်၌ကိုက လည်းကောင်းကို ခြုံ့တာပါ။ ၎င်း ကို ထပ်ခြုံချင်တဲ့အခါမှာတော့ ၎င်း သင်္ကေတပေါ် ကင်းစီးတင်ပြီး ၎င်း င်္ ရယ်လို့ ရေးပါတယ်။ အဲဒါကြောင့် ၎င်း သင်္ကေတမှာ ငသတ် ဝစ္စပေါက်ဖြုတ်ထားတာဖြစ်ပါတယ်။ ယူနီကုဒ် 1.0 မူကြမ်းမှာ ၎င်း သင်္ကေတနဲ့ ဿကြီး 5.1 မူအတိုင်း ပါပါတယ်။

၅။ 
အပေါ်က သဝေထိုးကို ရှေးက ဗမာစာ၊ မွန်စာတွေမှာ သုံးပါတယ်။ ခုခေတ်လည်း မွန်စာတွေမှာ သုံးနေတုန်းပါပဲ။ ဥပမာ – “ယဵု”။ အသုံးလိုတိုင်းယူနီကုဒ်မှာ လိုက်ထည့်နေရမလားဆိုတော့ ဟုတ်ပါတယ် လိုက်ထည့်ရမှာပါ။ သုံးတဲ့အသုံး၊ ဘယ်နေရာမှာသုံးတယ်၊ ဘယ်ခုနှစ်က ဘယ်တိုင်းရင်းသားရဲ့ ဘယ်စာမှာသုံးတယ်ဆိုတာ ပြနိုင်ရင် ယူနီကုဒ်ကွန်ဆိုတီယမ်မှာ ထပ်တိုးတောင်းလို့ ရပါတယ်။ ကုဒ်ပွိုင့်တစ်ခုချင်းစီဟာ ရဖို့ အင်မတန်ခက်ခဲတဲ့အတွက် အသစ်ရမယ်ဆိုရင် ဒါဟာ ဝမ်းသာအားရ ကြိုဆိုရမယ့် အချက် ဖြစ်ပါတယ်။
၆။ 
Normalization အတွက်လားဆိုရင် ဟုတ်ပါတယ်လို့ ဖြေရပါမယ်။ Alternate rule for normalization ဆိုတာ ရှိရင် ပိုအကျိုးရှိပါတယ်။ ရဖို့လည်း ခက်ပါတယ်။ ဥလုံးကြီးတင်ဆန်ခတ်နဲ့ မှားနိုင်စရာ တခြားစာလုံးမရှိတာရယ်၊ ရှောင်ဖို့ခက်တဲ့ သာဓကအများအပြားရယ်ကြောင့် ထည့်ပေးလိုက်တာပါ။ လက်ကွက်မှတ်မိရင် 1025+102E အစား 1026 အက္ခရာ ဦ ကိုသာသုံးဖို့ တိုက်တွန်းပါတယ်။
၇။ 
ဪ သရအတွက် မွန်စာမှာ ရှေ့ပစ်သုံးပြီး ပြပါတယ် – “အဴ”။ ဗမာစာမှာ ရှေ့ပစ်မသုံးတော့ဘဲ ဝသတ်နဲ့ ပြပါတယ် – “ဝ်”။ သဝေထိုးနဲ့ ရေးချသုံးတဲ့ အော်သံမှာ ရှေ့ပစ်နဲ့ဆင်တဲ့ ရှေ့ထိုးကို သုံးပြီး ပုံစံအသစ်ရေးပါတယ်။ ကုန်းဘောင်ခေတ် တောင်တွင်းဆရာတော် ခင်ကြီးဖျော်ရဲ့ သဒ္ဒဗျူဟာကျမ်းမှာတော့ အော်သရအတွက် အက္ခရာဩမှာ သဝေထိုးရေးချ ရှေ့ထိုးကပ်ပြီး အက္ခရာဪကို စထွင်ပါတယ်။ ဒါပေမဲ့ အက္ခရာဩ အက္ခရာဪတွေကို သ ရရစ် လို့ မရေးပါ။ မွန်စာမှာ အက္ခရာဩ ရော သ ရရစ် အသုံးပါ ရှိတဲ့အတွက်ကြောင့် ဖြစ်ပါတယ်။ ဥပမာ – “သြန်” (သကို ရရစ်ကပ်ရင် ဆလိမ်+အောသံထွက်ပါတယ်)။

၈။ 
၁၉၉၈ ယူနီကုဒ်(၃) မြန်မာစာ Proposal မှာ အော နဲ့ အော် သရနှစ်လုံးပါပါတယ်။ ဒါပေမဲ့ သရလို့ဆိုတဲ့ အ ကိုယ်၌က ဗျည်းထဲဝင်နေတဲ့အချက်ကြောင့်ရယ် အို အုံ အံ အသုံးတွေ အတွက်ကြောင့်နဲ့ အ ကိုသုံးပြီး ရှိပြီးသားသရတွေဖြစ်တဲ့ သဝေထိုး၊ ရေးချတို့နဲ့ ရေးလို့ဖြစ်တယ်ဆိုပြီး နောက်ပိုင်းမှာ ပြန်ဖြုတ်ပါတယ်။ ဗျည်းမှာ အ မပါတဲ့ ခမာကိုတော့ အော အော် နှစ်လုံး ပေးပါတယ်။ ယူနီကုဒ်ပွိုင့်လေး တစ်လုံးတစ်ပါဒအတွက် မြန်မာစာပညာရှင်၊ ကွန်ပျူတာပညာရှင်ေတွ ဖြစ်နိုင်ချေရှိတဲ့ နည်းလမ်းပေါင်းစုံသုံးပြီး အကြိမ်ကြိမ် ခေါင်းချင်းဆိုင်ဆွေးနွေး၊ ပြည်ပကိုအခါခါထွက်၊ ဆုံးဖြတ်ချက်ကို လည်တရှည်ရှည်နဲ့စောင့်ဖူးခဲ့ပါပြီ။
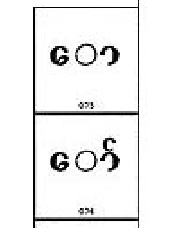
၉။ 
ယူနီကုဒ်အက္ခရာတွေမှာ မြန်မာအက္ခရာတွေအတွက် ဘလော့ခ် အစုအဝေးကြီးတစ်ခု ထားပေးပြီး ပုံစံကျအောင် စီပါတယ်။ ဗားရှင်းတစ်ခုချင်းစီ သွားတိုင်း မလိုတာပယ် လိုတာဖြည့်လုပ်ပါတယ်။ အဲဒီအခါမှာ အရင်ဗားရှင်းတွေနဲ့ အတတ်နိုင်ဆုံးတူအောင် ပြန်ချန်ထားရပါတယ်။ ဗမာစာဟာ မွန်စာကို ယူသုံးထားပါတယ်။ မွန်စာမှာလည်း ဗမာစာမှာမရှိတဲ့ အက္ခရာတွေ ပါပါတယ်။ ရှမ်းစာ မွန်စာ ရခိုင်စာ ကရင်စာ မှာလည်း ဗမာအက္ခရာကို သုံးပါတယ်။ ကျီးဖြူဒီမှာနေ၊ ကျီးမည်းဒီကိုသွားဆိုပြီး ခွဲထုတ်လို့မရနိုင်ပါဘူး။
၁၀။ 
ယူနီကုဒ်ဖောင့်တွေဖြစ်တဲ့ မြန်မာ၃၊ မိုင်မြန်မာ၊ ပိတောက်၊ ပုရပိုက်၊ ယွန်းချို၊ မာစတာပိယူနီစံတွေမှာ ရှားရှားပါးပါး ပါဠိသက် တစ်နေရာ နှစ်နေရာကလွဲလို့ အားလုံးအတူတူ အလုပ်လုပ်ပါတယ်။ အခုဒီစာကိုလည်း Mac မှာ မာစတာပိယူနီစံနဲ့ ရိုက်ပြီး မွန်စာတွေ မြင်ရအောင် Windows မှာ ပိတောက်နဲ့ PDF ပြန်ထုတ်ပါတယ်။
၁၁။ ဒါကတော့ ညီလင်းဆက်ထဲမှာ မပါပေမဲ့ ယူနီကုဒ်က ပါဠိသုံးထပ်ဆင့် မရဘူးလို့ ကတ်ကတ်သတ်သတ် ပြောသူတွေ ရှိလာတာကြောင့် တစ်လက်စတည်း ထည့်ရေးဖြစ်ပါတယ်။ ယူနီကုဒ် Encoding မှာ မြန်မာဘာသာအတွက် Encode လုပ်လို့မရဘူးဆိုတာ မရှိသလောက် ဖြစ်နေပါပြီ။ ဖောင့်အနေနဲ့ အမှန်မပြနိုင်တာတွေ ရှိကောင်းရှိပါမယ်။ ဥပမာ –
န + ဝိရာမ + တ + ဝဆွဲ ဆိုတဲ့ ပါဠိသုံးထပ်ဆင့် စာလုံးပါ။

သူ့ကို အခု မြန်မာ၃နဲ့ အမှန်မမြင်ရပေမဲ့ သုံးမှဖြစ်မယ်ဆိုပြီးလိုအပ်လာခဲ့လို့ ရှိရင် ယူနီကုဒ် Encoding စာလုံးစီပုံ ရှိပြီးသား ဖြစ်တဲ့အတွက် ဖောင့်မှာ Glyph တစ်ခုနဲ့ Rule တစ်ခု ပေါင်းထည့်လိုက်ရုံနဲ့ ရပါပြီ။
Encoding ဆိုတာနဲ့ တစ်ဆက်တည်း ပြောလိုက်ပါဦးမယ်။ ယူနီကုဒ် Encoding Model မှာ ဘယ်အက္ခရာက ရှေ့ကနေပြီး ဘယ်အက္ခရာက နောက်ကနေမယ်ဆိုတာ အတိအကျ ဖော်ပြထားတဲ့ စည်းမျဉ်းတွေ ရှိပါတယ်။ Encoding ဆိုတာ မြန်မာစာ သင်ရိုး မဟုတ်ပါဘူး။ တခြားတိုင်းရင်းသားအက္ခရာတွေနဲ့ အဆင်ပြေအောင်၊ ကွန်ပျူတာမှာ တွက်ချက်ရ လွယ်ကူအောင် နောင်အရှည်မှာ အဆင်ပြေလွယ်ကူအောင် ဘာသာဗေဒနည်း အရ ကွန်ပျူတာမှာ Syllable ဝဏ္ဏအဆင့် သိမ်းတဲ့နည်း ဖြစ်ပါတယ်။ အလွယ်မှတ်ရင်တော့ ဗျည်း၊ ဗျည်းတွဲ၊ သရ လို့ မှတ်နိုင်ပါတယ်။ စိတ်ဝင်စားရင် ဒီနေရာမှာ အလွယ်မှတ်နည်း အဆင့်ဆင့်ကို သွားကြည့်နိုင်ပါတယ်။ အကျယ်ကိုတော့ ဒီမှာ ကြည့်ပါ။
နောက်ဆုံးတစ်ခုပြောချင်တာက ယူနီကုဒ်ဟာ မြန်မာစာ ကောင်းကောင်းမတတ်တဲ့ ကွန်ပျူတာသမားတွေ လုပ်ချင်ရာ လုပ်ထားကြတာ မဟုတ်ဘူး ဆိုတာပါပဲ။ မြန်မာစာပညာရှင်တွေ၊ တိုင်းရင်းသားစာပေ ပညာရှင်တွေ၊ ဘာသာဗေဒကို အထူးပြု လေ့လာနေတဲ့ လူတွေ၊ ကွန်ပျူတာပညာရှင်တွေ အားလုံး ဝိုင်းဝန်းပြီး လုပ်ထားကြတာပါ။ လုပ်တိုင်းလည်း မြန်မာတွေ စိတ်ကြိုက် အားလုံး မရပါ။ အရှေ့တောင်အာရှဘာသာစကားတွေကို အထူးပြုလေ့လာထားတဲ့ ယူနီကုဒ်ကွန်ဆိုတီယမ်က ပညာရှင်တွေရဲ့ အဆင့်ဆင့် စိစစ်မှုကို ခံကြရပါသေးတယ်။ ယူနီကုဒ် Proposal တစ်ခုတင်ဖို့ နဲ့ တင်ပြီးရင် အတည်ပြုဖို့ တစ်နှစ်ကြာပါတယ်။ အဲဒီကာလတွေအတွင်းမှာ အကြောင်းပြချက်ခိုင်လုံရင် ပြင်ခွင့် ကန့်ကွက်ခွင့် ရှိပါတယ်။ အဲဒါတွေအားလုံး ပြီးသွားတော့မှ အတည်ပြုတဲ့ ဗားရှင်းတစ်ခုရပါတယ်။ အခု ဗားရှင်း 5.2 မှာ ဗမာစာအတွက် ပြင်စရာ ကုန်သလောက်ဖြစ်သွားပါပြီ။ ဒါကြောင့် စိတ်ချသုံးလို့ ရပါပြီလို့ ပြောနေကြတာပါ။ လူသိနည်းတဲ့ တိုင်းရင်းသားစာတွေ ထည့်ဖို့ရှိလာတယ်ဆိုလည်း အခုရှိပြီးသားအက္ခရာတွေရဲ့ နောက်မှာ ထပ်ထည့်သွားရုံပါပဲ။ ဒီလောက်ဆိုရင် ဒွိဟဖြစ်နေသူ အတော်များများ ရှင်းသွားလောက်ပြီ ထင်ပါတယ်။
Credit: Lionslayer @ myanmarlanguage.org
Ref:
- All Myanmar Unicode Proposals and revisions (1996-2008)
- A HISTORY OF THE MYANMAR ALPHABET (1994)
- Khmer – Unicode Consortium
- Myanmar – The Unicode Standard (6.0)
- Han Unification in the Unicode Standard
- Sealang Mon Lexicon
- http://www.mrc-usa.org/
- Proposed PDAM for ISO/IEC 10646-1: 1993/Amd. xx: 1998 (E)
- Myanmar Unicode Research Papers & Reference Documents
- http://unicode.org/notes/tn11/UTN11_3.pdf
- http://std.dkuug.dk/jtc1/sc2/wg2/docs/n3043.pdf